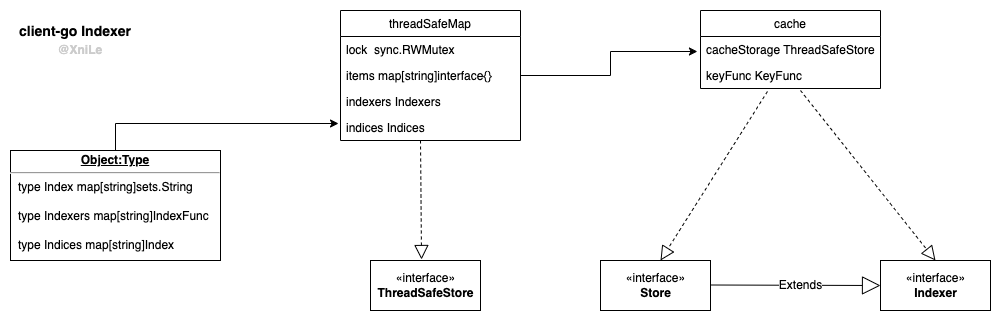
在上一篇client-go概览中已经介绍过Indexer,但当我在看源码时发现它还是比较复杂的,为了加深理解便有了这篇笔记,先放一张总览图
Store
通用存储接口,提供最基本的数据操作能力。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
type Store interface {
// Add adds the given object to the accumulator associated with the given object's key
Add(obj interface{}) error
// Update updates the given object in the accumulator associated with the given object's key
Update(obj interface{}) error
// Delete deletes the given object from the accumulator associated with the given object's key
Delete(obj interface{}) error
// List returns a list of all the currently non-empty accumulators
List() []interface{}
// ListKeys returns a list of all the keys currently associated with non-empty accumulators
ListKeys() []string
// Get returns the accumulator associated with the given object's key
Get(obj interface{}) (item interface{}, exists bool, err error)
// GetByKey returns the accumulator associated with the given key
GetByKey(key string) (item interface{}, exists bool, err error)
// Replace will delete the contents of the store, using instead the
// given list. Store takes ownership of the list, you should not reference
// it after calling this function.
Replace([]interface{}, string) error
// Resync is meaningless in the terms appearing here but has
// meaning in some implementations that have non-trivial
// additional behavior (e.g., DeltaFIFO).
Resync() error
}
|
Indexer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
// Indexer extends Store with multiple indices and restricts each
// accumulator to simply hold the current object (and be empty after
// Delete).
//
// There are three kinds of strings here:
// 1. a storage key, as defined in the Store interface,
// 2. a name of an index, and
// 3. an "indexed value", which is produced by an IndexFunc and
// can be a field value or any other string computed from the object.
type Indexer interface {
Store
// Index returns the stored objects whose set of indexed values
// intersects the set of indexed values of the given object, for
// the named index
Index(indexName string, obj interface{}) ([]interface{}, error)
// IndexKeys returns the storage keys of the stored objects whose
// set of indexed values for the named index includes the given
// indexed value
IndexKeys(indexName, indexedValue string) ([]string, error)
// ListIndexFuncValues returns all the indexed values of the given index
ListIndexFuncValues(indexName string) []string
// ByIndex returns the stored objects whose set of indexed values
// for the named index includes the given indexed value
ByIndex(indexName, indexedValue string) ([]interface{}, error)
// GetIndexer return the indexers
GetIndexers() Indexers
// AddIndexers adds more indexers to this store. If you call this after you already have data
// in the store, the results are undefined.
AddIndexers(newIndexers Indexers) error
}
|
Indexer在Store基础上扩展了一些新功能,至于扩展了什么功能?看到名字可能会猜是索引,网上确实有很多文章解释说是扩展了索引功能,言外之意就是 Store没有索引功能,我个人是不太认同此说法的,我更倾向于理解是扩展了多索引的能力,因为稍后分析
cache
1
2
3
4
5
6
7
8
9
|
// `*cache` implements Indexer in terms of a ThreadSafeStore and an
// associated KeyFunc.
type cache struct {
// cacheStorage bears the burden of thread safety for the cache
cacheStorage
// keyFunc is used to make the key for objects stored in and retrieved from items, and
// should be deterministic.
keyFunc KeyFunc
}
|
cache 实现了Indexer接口,当然也实现了Store接口
cache组成:
- cacheStorage 实现
ThreadSafeStore接口
- keyFunc 存储对象时时用来计算对象的key
ThreadSafeStore
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
type ThreadSafeStore interface {
Add(key string, obj interface{})
Update(key string, obj interface{})
Delete(key string)
Get(key string) (item interface{}, exists bool)
List() []interface{}
ListKeys() []string
Replace(map[string]interface{}, string)
Index(indexName string, obj interface{}) ([]interface{}, error)
IndexKeys(indexName, indexKey string) ([]string, error)
ListIndexFuncValues(name string) []string
ByIndex(indexName, indexKey string) ([]interface{}, error)
GetIndexers() Indexers
// AddIndexers adds more indexers to this store. If you call this after you already have data
// in the store, the results are undefined.
AddIndexers(newIndexers Indexers) error
// Resync is a no-op and is deprecated
Resync() error
}
|
仔细看ThreadSafeStore接口的方法名会发现它和Indexer接口方法名一样,不同的只是方法的参数,Indexrer中是直接传对象而这里是传k,v,同时从名字上也能看出它也应该是并发安全的。
threadSafeMap
1
2
3
4
5
6
7
8
9
10
|
// threadSafeMap implements ThreadSafeStore
type threadSafeMap struct {
lock sync.RWMutex
items map[string]interface{} //存放对象
// indexers maps a name to an IndexFunc
indexers Indexers
// indices maps a name to an Index
indices Indices
}
|
client-go缓存下来的数据最后是怎么保存的呢?到这里神秘面纱终于被揭开了,它是用一个并发安全的map来保存的,从apiserver获取到的kubernetes对象数据会以k,v形式保存。 items存放对象数据,哪indexers 和 indices又是做什么用的呢?我们接着往下分析。
indexers 和 indices
1
2
3
4
5
6
7
8
|
// Index maps the indexed value to a set of keys in the store that match on that value
type Index map[string]sets.String
// Indexers maps a name to a IndexFunc
type Indexers map[string]IndexFunc
// Indices maps a name to an Index
type Indices map[string]Index
|
- Index 索引,k,v 结构,value是集合结构,所以会去重
- Indexers 我称它为索引的索引,k,v结构,key是检索索引的名字,value是生成索引key的函数
- Indices 我称它为二维索引
我在初次看到这里时会有代码都能看懂但放一起看不懂的感觉:为什么要设计成这样,纵观整个client-go,存储这一层不应该就是做为etcd的本地缓存用来存储kubernetes资源对象吗?一个k,v结构就能解决为啥还需要多重索引的功能呢?于是我去翻了一遍kubernetes自身各种controller后我才明白大多时候确实只需要一个k,v,但当需要存储一些额外的信息时显示一个k,v是不够的,我们来看下daemonset控制器的一段代码:
1
2
3
4
|
// This custom indexer will index pods based on their NodeName which will decrease the amount of pods we need to get in simulate() call.
podInformer.Informer().GetIndexer().AddIndexers(cache.Indexers{
"nodeName": indexByPodNodeName,
})
|
1
2
3
4
5
6
7
8
9
10
11
|
func indexByPodNodeName(obj interface{}) ([]string, error) {
pod, ok := obj.(*v1.Pod)
if !ok {
return []string{}, nil
}
// We are only interested in active pods with nodeName set
if len(pod.Spec.NodeName) == 0 || pod.Status.Phase == v1.PodSucceeded || pod.Status.Phase == v1.PodFailed {
return []string{}, nil
}
return []string{pod.Spec.NodeName}, nil
}
|
可以看出用一个额外的nodeName Index来存储pod.Spec.NodeName,至此是不是解释了我们上边的疑问,明白了为什么要这样设计,同时从这里也说明了Indexer相较Store增加了多索引的能力。
Index、Indexers、indices 名字有点绕,我觉得叫什么不重要,重要的是要理解它的作用,为了让大家直观的看出它们的作用我画了一张图方便理解。
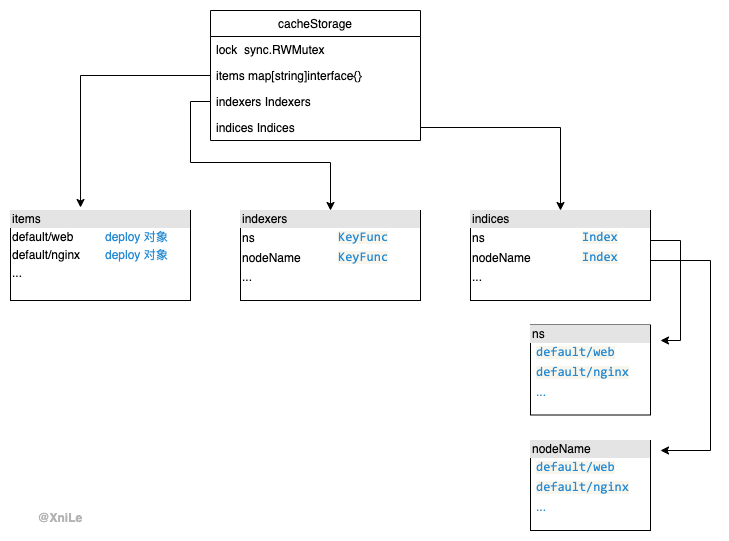
具体数据是数据更新逻辑在updateIndices函数:
1
2
3
4
5
6
7
|
func (c *threadSafeMap) Add(key string, obj interface{}) {
c.lock.Lock()
defer c.lock.Unlock()
oldObject := c.items[key]
c.items[key] = obj
c.updateIndices(oldObject, obj, key)
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
func (c *threadSafeMap) updateIndices(oldObj interface{}, newObj interface{}, key string) {
// if we got an old object, we need to remove it before we add it again
if oldObj != nil {
c.deleteFromIndices(oldObj, key)
}
for name, indexFunc := range c.indexers {
indexValues, err := indexFunc(newObj)
if err != nil {
panic(fmt.Errorf("unable to calculate an index entry for key %q on index %q: %v", key, name, err))
}
index := c.indices[name]
if index == nil {
index = Index{}
c.indices[name] = index
}
for _, indexValue := range indexValues {
set := index[indexValue]
if set == nil {
set = sets.String{}
index[indexValue] = set
}
set.Insert(key)
}
}
}
|
到这里也就解释了上边我们为什么说Indexer扩展了Store的多索引能力,因为数据最终都是以k,v结构存放,通过key获取数据,不同是Indexer可以存放多k,v
总结
至此Indexer已经介绍完毕,剖析整个源码我们不仅对clien-go本地缓存细节有了一全面了解,同时它把功能抽象不同层次,面向接口开发的设计理念也很受启发。