Kubernetes Eviction 驱逐机制分析
文章目录
当节点资源不足时,kubelet 会主动终止优先级较低的 Pod 以回收资源防止饥饿,kubernetes 将这个过程称为Eviction ,本文将结合源码探究它的运作机制。
分析基于:kubernetes-1.28.4
由于 Eviction 中有很多概念,为了方便理解驱逐的设计思路,在正式开始分析源码前我们先来了解下它们。
Eviction signals
驱逐信号,如果按字面意思的好像是在说驱逐后产生的信号,其实应该理解成输入给 Eviction 控制器的信号,用来告诉控制器应该关注哪些指标,当发现它们超门限后好采取行动,对于Linux系统共有6种信号指标。
| Eviction Signal | Description |
|---|---|
memory.available |
memory.available := node.status.capacity[memory] - node.stats.memory.workingSet |
nodefs.available |
nodefs.available := node.stats.fs.available |
nodefs.inodesFree |
nodefs.inodesFree := node.stats.fs.inodesFree |
imagefs.available |
imagefs.available := node.stats.runtime.imagefs.available |
imagefs.inodesFree |
imagefs.inodesFree := node.stats.runtime.imagefs.inodesFree |
pid.available |
pid.available := node.stats.rlimit.maxpid - node.stats.rlimit.curproc |
分别表示节点内存、磁盘、磁盘 inode、镜像磁盘、镜像磁盘 inode、PID 剩余情况,它们在代码中的定义
Eviction thresholds
驱逐阈值或门限,告诉驱逐控制器在满足什么条件下应该驱逐 Pod,其形式为[eviction-signal][operator][quantity]。
eviction-signal指标;operator运算符,用来判断是否达到阈值;quantity阈值,可以是具体数值,也可以是百分比的形式。
源码内部用 Threshold 表示。
根据是否有宽限期,驱逐门限分两种,Soft eviction thresholds 和 Hard eviction thresholds
Soft eviction thresholds
指标达到阈值后并不会立即开始驱逐流程,而是根据配置设置一个宽限期,如果在宽限期指标降到阈值下则不进行驱逐,否则如果在宽限期到了后指标仍然没有降到阈值以下则会开始驱逐流程。
相关配置:
-
eviction-soft: 阈值 -
eviction-soft-grace-period: 宽限期,表示达到阈值后到开始驱逐动作之前的时间。 -
eviction-max-pod-grace-period: 满足驱逐条件需要 Kill Pod时等待Pod优雅退出的时间。The maximum allowed grace period (in seconds) to use when terminating pods in response to a soft eviction threshold being met.
官方对这个参数的命名和解释是有争议的,一眼没法弄清它使用和``的区别,有个与此相关的Issue,我个人第一看到这个参数和解释时也是一脸蒙逼,控制满足软驱逐条件到正式驱逐Pod的最大宽限时间?真到看源码我才弄明白它的作用。
Hard eviction thresholds
硬驱逐门限没有宽限期,指标达到门限后便会立即开始驱逐流程。相关配置:
memory.availablenodefs.availableimagefs.availablenodefs.inodesFree
除此之外,kubelet 还提供了其他的驱逐参数:
- **eviction-pressure-transition-period:**驱逐等待时间。当节点出现资源饥饿时,节点需要等待一定的时间才一更新节点 Conditions ,然后才开启驱逐
Pod,默认为5分钟。该参数可以防止在某些情况下,节点在软驱逐条件上下振荡而出现错误的驱逐决策。 - **eviction-minimum-reclaim:**表示每一次驱逐必须至少回收多少资源。该参数可以避免在某些情况下,驱逐
Pod只会回收少量的资源,导致反复触发驱逐。
Threshold Notifier
什么是 Notifier 呢?
有了指标,有了门限,怎么知道指标是否超门限呢?
通常会用于一个后台进程不断轮询获取指标当前值然后和阈值比较判断是否超门限。
没错驱逐控制器就是这么干的,那除了被动获取外,能不能有一种机制能在指标超门限后主动通知控制器呢,没错,有的,这就是Threshold Notifier 。
怎么实现呢,背景知识:
cgroups通知API允许用户空间应用程序接收有关cgroup状态变化的通知,但目前,通知API只支持监控内存溢出(OOM),关于通知API可以看下 Using the Notification API
kubenretes 依靠 Using the Notification API 能实现内存 Threshold Notifier,相关逻辑下边两个文件中:
对如何实现感兴越的话,可以自行看下这两个文件。
有了上边这些知识点后接下来我们进入主题,分析驱逐控制器是如何工作的?
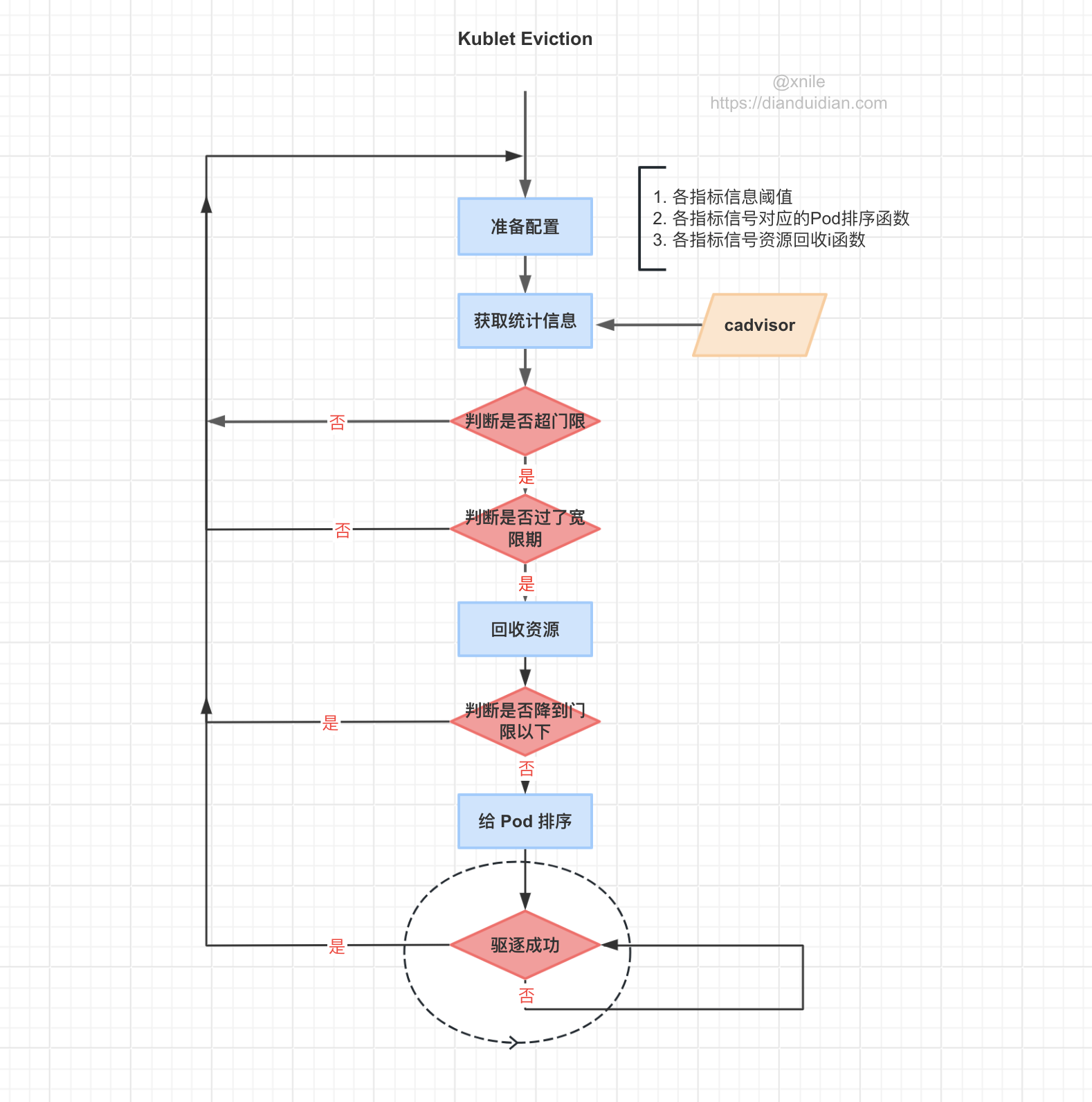
synchronize
m.synchronize 是 kubelet 驱逐 Pod 的核心方法,因此我们重点来看它。
|
|
函数主要逻辑:
-
准备各种
Eviction Signal的阈值,后边会用到,根据它们来判断是否超门限,它们从哪获取呢?由kubelet 启动时通过启动参数或你配置文件指定; -
准备给 Pod 排序的函数,需要考虑
imagFs是否是独立磁盘的情况。什么作用呢?当某个资源指标超门限后,我怎么知道要先驱哪个 Pod,后驱逐哪个 Pod。每种 Signal 都有自己的排序函数,具体看buildSignalToRankFunc -
硬盘等能压缩的资源支持回收,为它们准备回收函数,后回收资源时会用到,同样需要考虑
imagFs是否是独立磁盘的情况。 -
获取节点上当前 active 的
Pod列表,后边会从它们中最多选取一个驱逐; -
使用
cadvisor采集的数据汇总各种资源统计信息 ; -
使用 Cgroups Notification API 更新内存资源统计信息;
-
根据上边获取到的各资源统计信息组装 signalObservations 方便后边会用到;
-
thresholdsMet 将获取到的资源统计信息同阈值比较筛选出超门限的,得到 Threshold 列表;
-
对于上一次轮训时超标记为超限资源,本次还要考虑
--eviction-minimum-reclaim配置的最小回收情况。 -
确定超门限 Threshold 列表它们第一次超门限的时间,用于后边判断宽限期;
-
根据当前超限情况准备 node conditions ,用于更新 node status;
-
确定各 NodeConditionType 上一次观察的时间,目的用于下边判断是否满足 config.PressureTransitionPeriod;
-
判断节点 Condition 是否满足等待时间,避免 Condition 状态震荡;
-
筛选出超限且持续了 grace periods 的 thresholds,对于软驱逐由 –eviction-soft-grace-period 指定,硬驱逐为0;
-
保存 nodeConditions 、thresholdsFirstObservedAt 、nodeConditionsLastObservedAt、thresholds
-
由于各种资源的统计也不是实事更新的,也是定时轮训获取的,所以可能会出现上次轮询时已经驱逐过一个 Pod,但是本次轮询由于资源统计还没更新,观察判断仍然超限,这样是不准确的,需要忽略掉。thresholdsUpdatedStats 的作用就是去除掉这些资源状态末刷新的超限。
-
本地临时存储容量隔离特性
-
Signals 背后对应内存,磁盘,inode,pids 各种资源,它们分可压缩资源和不可压缩资源,可压缩资源是可以回收的,所以需要按是否支持回收给它们排个序,后边按这个顺序回收资源,内存资源会排在其它资源前。为什么内存会排在最前边呢,明明它是不可回收资源啊?不支持回收反而在最前边,乍一看矛盾了。其实这里逻辑比较巧妙,正因为内存是不可压缩资源,回收对它没啥效果,所以当它发生饥饿时应该立即开始驱逐。相反如果把其它可压缩的资源放在前边,先回收它们会出现骚操作一通内存可是一点也没减的情况。它这样把内存放到最前边,表面看是资源回收时先走它,但是因为它不支持回收,没有回收函数,会快速略过;
-
getReclaimableThreshold 筛选出准备回收资源的 Threshold ;
-
reclaimNodeLevelResources 回收节点资源
-
准备给 Pod 排序的函数;
-
如果 activePods 为空,没有可供驱逐的
Pod则直接返回进入下一次轮询; -
给 activePods 排序;
-
遍历 activePods 开始驱逐 Pod,如果 Pod 成功驱逐则 return 返回,进入下一轮询过程,即每次轮询最多只驱逐一个 Pod。
为什么每次只驱逐一个 Pod 呢?背后的考量让人暖心,做到尽可能的少 kill, 虽然每次驱逐一个 Pod 可能资源降不到门限以下,大不了再 loop 一次。还有就是每个超限的 threshold 都是独立的,内存我只看内存超限,但一个Pod占用的资源并不是单一的,内存,磁盘都会占用,当我因为内存超门限驱逐它以后,硬盘占用也会减少,这时应该重新 observation 资源使用情况,而不能静态的使用已经 observation 过的资源使用情况。总结就是: 驱逐 -> 观察 -> 驱逐 -> …
Pod 选择排序
每种资源都有对应的排序方法,它们的定义在 buildSignalToRankFunc;
|
|
具体按什么来排序的呢?
|
|
rankMemoryPressure 、rankPIDPressure、 rankDiskPressureFunc 分别对应内存、PID、硬盘,当对应资源发生饥饿时就会使用对应排序函数选择 Pod Kill。
总结
- 软驱逐会等待一个宽限期,如果在宽限期内资源使用降到门限以下,资源不再饥饿则不驱逐;驱逐时会等待 Pod 优雅退出,其时间为
eviction-max-pod-grace-period为配置的值,其实际是覆盖了 pod.Spec.TerminationGracePeriodSeconds; - 硬驱逐没有宽限期,且Kill Pod 不会等待 Pod 优雅退出,即 grace Period 为0;
- 驱逐前会回收资源,如果资源仍然饥饿则会开始驱逐
Pod; - 对于本此超门限的资源,下次运行判断是否超门限时还会把 Minimum eviction reclaim 最小回收配置考虑进去;
- 为了避免 Node conditions 状态震荡,节前资源饥饿状态转变前会等待一个 eviction-pressure-transition-period, 默认为 5 分钟。
- 每种饥饿资源都有对应的选取 Pod 的排序函数,对应关系见 buildSignalToRankFunc;
参考
https://kubernetes.io/docs/concepts/scheduling-eviction/node-pressure-eviction/
https://www.cnblogs.com/lianngkyle/p/16652129.html
https://cloud.tencent.com/developer/article/1690175
https://kubernetes.io/blog/2022/09/19/local-storage-capacity-isolation-ga/
https://sysdig.com/blog/kubernetes-pod-evicted/
https://www.jianshu.com/p/f2403e33c766
https://github.com/kubernetes/kubernetes/issues/64530
https://kubernetes.io/docs/reference/config-api/kubelet-config.v1beta1/
文章作者 XniLe
上次更新 2024-01-16